任何一个服务在有限资源前提下都会存在处理能力的上限。本文主要描述限流的一些主要算法。
流控 (Rate limiting) 通过限制每个用户调用 API 的频率来保护你的 API。保护 API 被无意或者恶意的滥用。没有流控,每个用户可以无限制的发送请求。这会导致请求的毛刺,使得其它用户饥饿(译者注:得不到服务)。开启流控后,用户在每秒内发送请求个数限制到一个固定的数字。
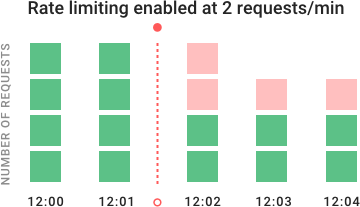
在上面示例图中,你可以看到流控如何随着时间阻止请求。API 初始时每分钟收到 4 个请求(绿色)。在 12:02 开启流控,额外的请求被拒绝(红色)。
流控对于公开的 API 而言非常重要。它可以为每个用户维持好的服务质量,甚至当部分用户使用超出他使用的比例。计算密集型的节点尤其需要流控,特别是由自动扩容服务提供服务或者按计算收费的服务例如:AWS Lambda 和 OpenWhisk 服务的节点。你也可以限制提供敏感数据的 API 访问,因为这可以限制攻击者在未知情况下获取权限时数据的暴露。
流控算法
流控由很多种算法,各自有优缺点。让我们依次研究,这样你就可以选择最适合你需求的算法。
Leaky Bucket (漏桶)
漏桶(和令牌桶类似) 是一个简单,直观的流控算法。它使用一个队列,你可以认为是一个存放请求的桶。当请求到达后,请求会被添加到队列。正常情况下,会先处理队列的头。这种队列也是 FIFO 队列。当队列满后,额外的请求会被丢弃(漏掉)。
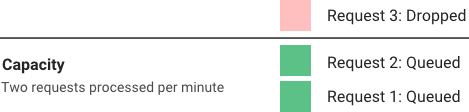
这个算法的优势是平滑掉突发的请求,以一个平均的速率来处理。而且在单机或者负载均衡器上实现。给定有限队列大小的条件下,内存也比较高效。
但是突发的流量可以很快填满队列(旧的请求),最新的请求会得不到服务(饥饿)。而且它也不能保证请求在固定时间内处理完。此外如果负载均衡的服务器由于容错或者流量增加对服务器的请求进行平衡时,你必须使用一个策略来协调以保证多个节点之间的速率限制。后面我们会讨论分布式环境下的挑战。
Fixed Window (固定窗口)
在固定窗口的算法中,用一个大小为 n 秒(通常使用可读性高的值,例如 60 或者 3600 秒)的窗口来限制速率。每一个请求会增加窗口中的计数器。如果计数器超过一个门限,请求会被丢弃。窗口通常会被定义为当前时间戳的向下求整。12:00:03 在 60 秒的窗口长度中为被取整为 12:00:00。
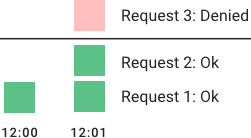
这个算法的优势是保证最近的请求得到处理,防止新的请求被旧的请求阻塞导致饥饿。然而在时间边界点的突发请求可以导致处理请求加倍,因为它在短时间内允许当前和下一个时间窗口的请求。此外,如果大量用户等待窗口的重置(译者注:下一个时间窗口),例如在每个小时的开始处,那么他们可能同时涌向向你的 API。
Sliding log (滑动日志)
滑动日志流控对每个用户请求都记录一条时间相关的日志。这些日志通常按照时间排序存储于哈希集合或者哈希表。超过门限的时间戳会被丢弃。当一个新的请求到来时,我们会求记录的和,来确定请求速率。如果请求超过限制速率,请求被拒绝。
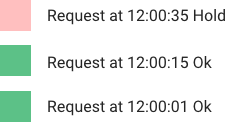
算法的优势是它没有固定窗口算法的边界问题。速率控制可以控制地很精确。而且滑动日志是针对每个用户的,也不会有蜂拥请求的问题。但是对每一个请求都记录无限的日志开销大。而且由于每个请求都需要计算该用户之前请求的和,计算开销也比较大,而且还可能需要跨多个服务器计算(译者注:数据可能存放在多个机器上)。所以它针对大量突发请求以及拒绝服务的攻击扩展性不好。
Sliding window (滑动窗口)
滑动窗口综合了固定窗口的低计算开销和滑动日志在边界时改进。像固定窗口一样,对每一个固定窗口都会利用一个计数器来统计。接下来,我们根据当前时间戳,并且考虑前一个窗口的权重值来平滑突发请求。例如,如果当前窗口负载为 25%,那么我们对前一个窗口的计数的权重设为 75%。对于每一个请求需要增加的数据点相对少,允许跨集群的扩展性和分布式。
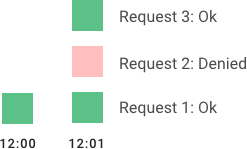
我们推荐滑动窗口,因为它支持扩展流控的灵活性和优秀的性能。速率窗口可以直观向用户展示流控的数据。同时它也避免漏桶的饥饿问题,以及固定窗口的边界突发请求问题。
分布式系统的流控
同步策略
在有多个节点的集群中,如果我们想保证一个全局速率限制,必须创建一个策略也来保证它。如果每个节点都记录它自己的速率,当一个用户请求发送给不同节点时,它可能超过全局的速率限制。事实上,节点数越多,用户越容易超过全局限制。
保证全局速率限制的最简单方式是在负载均衡器中增加会话,这样每个用户请求都发送给同样的节点。缺点是没法处理容错,以及当节点过载时难以扩展。
一个允许灵活的负载均衡规则的更好解决方法是使用一个中心的存储,例如 Redis 或者 Cassandra。中心存储会存储每个用户每个窗口的统计。这个方法的两个主要问题是:
- 由于需要访问存储,时延会增加
- 竞争条件(后面会讨论)
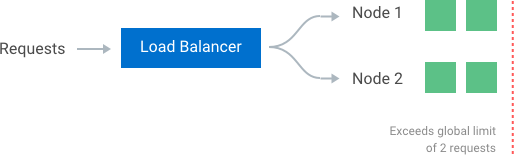
竞争条件
在高并发请求模式下,中心存储其中一个最大的问题是竞争条件。如果你获取当前流控计数,增加,然后写回存储使用的是简单的 get-then-set 方式时,竞争会发生。这种读写模型的问题是在读-增-存整个事件内会有其他请求到来,每个都会导致在一个非法(低)的计数上增加值。这会允许用户发送高频率的请求以旁路流控。

其中一个解决方法是对可能出问题的键增加一个锁,阻止其它进程区访问或者写对应的计数器。很快这又会变成主要的性能瓶颈,而且扩展性不好,特别是利用远程服务器,例如 Redis 来做后端的存储。
一个更好的方式是使用 set-then-get 的思路。它依赖高效实现“锁”的原子算子,允许你快速增加然后检查计数器的值,避免原子操作阻碍(译者注:成为性能瓶颈)。
性能优化
使用中心数据存储的另外一个缺点是检查流控计数器时引入的时延。不幸的是,即使使用 Redis 这种速度很快的存储也会对每个请求引入毫秒级的时延。
为了获得流控决定的最小时延,有必要在本地内存中检查计数器。可以通过放松速率检查的条件,使用最终一致性的模型。例如,每个节点创建一个同步周期,定时和中心存储同步。每个节点周期性的向中心存储推送它针对每个用户和窗口的计数器,中心存储自动更新这些值。然后节点获取更新后的值,更新至内存中。这种收敛->分歧->再次收敛周期性发生,最终集群中的每个节点都会同步。

每个节点收敛的周期速率需要可配。更短的同步间隔在流量分布到集群中的多个节点时(利用 round-robin 的负载均衡)会导致数据点更少的分歧;更长的同步间隔对数据存储的读写压力会较小,每个节点获取更新值得开销也会低。
Reference
翻译自: